Rspamd selectors settings
Rspamd selectors is a Lua framework that allows functional extraction and processing of data from messages.
Introduction
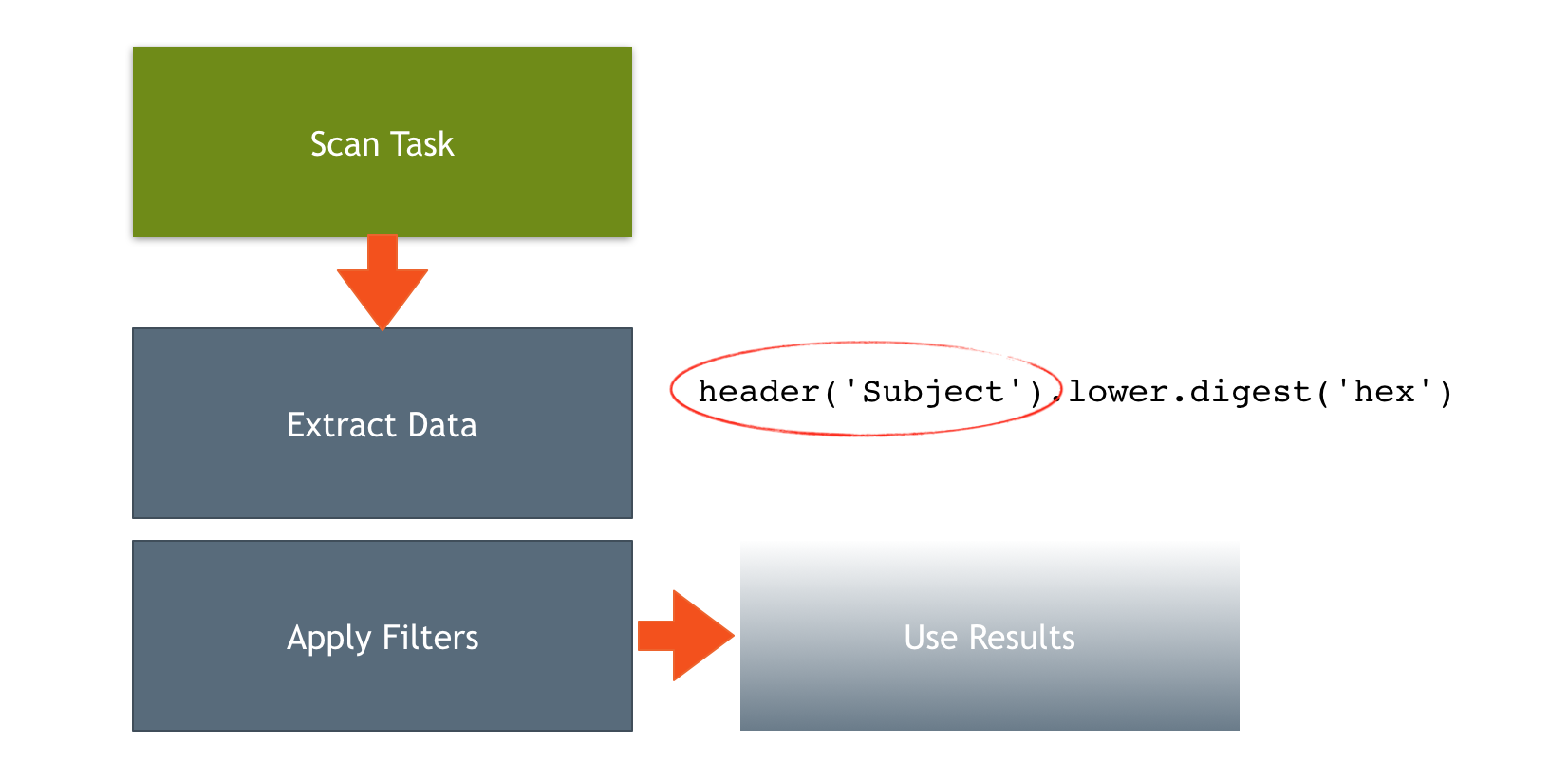
Starting from version 1.8, Rspamd introduces a framework designed for data extraction from messages and its subsequent utilization in plugins via transform functions. This functionality allows for a variety of operations. For instance, you can retrieve the SMTP from address and convert it to lowercase using the following selector:
smtp_from.lower
Similarly, you can obtain a lowercased digest of the subject and then truncate it to 16 hexadecimal characters:
header('Subject').lower.digest('hex').substring(1, 16)
Additionally, you have the capability to work with lists, such as lists of URLs:
urls:get_tld
Afterwards, these values can be used in various plugins:
multimap- map type equal toselectorratelimit- rate bucket description withselectorfieldreputation- generic selector rulesregexp- regular expressions based on selector’s datarbl- allows selectors in data queries- [
clustering] - TBD
Here is an example of Rspamd multimap rule that uses selectors to block bad Sendgrid senders using Invaluement SPBL:
# local.d/multimap.conf
INVALUEMENT_SENDGRID_ID {
type = "selector";
selector = 'header("X-SG-EID").id;from("smtp","orig").regexp("/^<?bounces\+(\d+)\-[^@]+@/i").last';
map = "https://www.invaluement.com/spdata/sendgrid-id-dnsbl.txt";
score = 6.0;
}
INVALUEMENT_SENDGRID_DOMAIN {
type = "selector";
map = "https://www.invaluement.com/spdata/sendgrid-envelopefromdomain-dnsbl.txt";
selector = 'header("X-SG-EID").id;from("smtp","orig"):domain.get_tld';
score = 6.0;
}
As evident from this rule, it skillfully employs a combination of map expressions and selectors to retrieve and modify data for queries within maps.
Selectors syntax
A selector typically consists of two key components:
- Data identification (such as
headerorurls) - An optional data transformation method, separated by a colon (
:) - A transformation pipeline, where multiple functions are linked with dot operators (
.)
Additionally, you can merge several selectors by using a semicolon (;) as a delimiter:
smtp_from.addr.lower;ip.addr
Both the data identification and transformation functions allow the use of arguments separated by commas. To simplify escaping, single and double quotation marks are supported:
header('Subject').regexp("^A-Z{10,}.*")
header('Subject').regexp("^A-Z{10,}\"'.*")
header('Subject').regexp('^A-Z{10,}"\'.*')
Data transformation method
Certain data extractors yield intricate objects or lists of such objects, including:
- table
- userdata (Lua object)
To convert these complex entities into simpler ones (strings or string lists), there are two approaches: implicit conversion and employing the method or table key extraction.
-
For objects, implicit conversion involves invoking the
tostringfunction, while the method call is straightforward. The following are equivalent:ip:to_string.lowerandip.lower. Nevertheless, different methods of the objects can be called:urls:get_tldwill return a list of strings containing all eSLD parts of URLs in the message. An exception to this rule (starting from 2.7) isrspamd_text, which can be traversed within the selector pipeline without any conversion. This exemption aims to retain large strings to prevent Lua string interning and excessive allocation. -
For tables, explicit conversion simply extracts the specified key, such as
from:addrorfrom('mime'):name. Implicit conversion is slightly more intricate:- If the table contains a field named
value, it is used for implicit conversion. - If not, and there is a field named
addrin the table, it is used for implicit conversion. - If neither of the above conditions are met,
table.concat(t, ' ')is used for implicit conversion.
- If the table contains a field named
Null values
If a data transformation function or any transform function returns nil, the selector is entirely disregarded. This characteristic is employed in functions like in and not_in. An illustrative configuration for the ratelimit module that combines the in transformation with id to exclude the original string is as follows:
user_workdays = {
selector = "user.lower;time('connect', '!%w').in(1, 2, 3, 4, 5).id('work')";
bucket = "10 / 1m";
};
user_weekends = {
selector = "user.lower;time('connect', '!%w').in(6, 7).id('weekends')";
bucket = "1 / 1m";
};
In this example, during weekends, the user_workdays selector will be entirely disregarded, and conversely, during working days, the user_weekends selector will not be utilized.
Selectors combinations
In the previous example, the selector comprised multiple components:
user.lower- extracts the authenticated username and converts it to lowercasetime('connect', '!%w').in(6, 7).id('weekends')- if the connection time falls within the specified range, it returns the string ‘weekends’
These two elements are separated by the ; symbol. Modules will utilize these elements as a concatenated string, for instance, user@example.com:weekends (the : symbol serves as a separator and is employed by the ratelimit module).
However, what if you want to achieve the same functionality for, let’s say, recipients:
rcpt_weekends = {
selector = "rcpts.take_n(5).lower;time('connect', '!%w').in(6, 7).id('weekends')";
bucket = "1 / 1m";
};
In this instance, we’re taking up to 5 recipients, extracting the address part, converting it to lowercase, and combining it with the string weekends if the condition is met. When a list of elements is concatenated with a string, this string is appended (or prepended) to each element of the list, resulting in the following:
rcpt1:weekends
rcpt2:weekends
rcpt3:weekends
It also works if you want to add a prefix and a suffix:
rcpt_weekends = {
selector = "id('rcpt');rcpts:addr.take_n(5).lower;time('connect', '!%w').in(6, 7).id('weekends')";
bucket = "1 / 1m";
};
This configuration will be transformed into:
rcpt:rcpt1:weekends
rcpt:rcpt2:weekends
rcpt:rcpt3:weekends
However, combining lists with different numbers of entries is not recommended – in this case, the shortest of the lists will be used:
id('rcpt');rcpts.take_n(5).lower;urls.get_host.lower
This will result in a list that might have up to 5 elements and will be concatenated with the prefix:
rcpt:rcpt1:example.com
rcpt:rcpt2:example2.com
rcpt:rcpt3:example3.com
Data definition functions
The data definition part specifies what needs to be extracted. Here is the list of methods currently supported by Rspamd:
| Extraction method | Version | Description |
|---|---|---|
asn |
1.8+ | Get AS number (ASN module must be executed first) |
attachments |
1.8+ | Get list of all attachments digests |
country |
1.8+ | Get country (ASN module must be executed first) |
digest |
1.8+ | Get content digest |
emails |
1.8+ | Get list of all emails. If no arguments specified, returns list of url objects. Otherwise, calls a specific method, e.g. get_user |
files |
1.8+ | Get all attachments files |
from |
1.8+ | Get MIME or SMTP from (e.g. from('smtp') or from('mime'), uses any type by default) |
header |
1.8+ | Get header with the name that is expected as an argument. The optional second argument accepts list of flags:
|
helo |
1.8+ | Get helo value |
id |
1.8+ | Return value from function’s argument or an empty string, For example, id('Something') returns a string ‘Something’ |
ip |
1.8+ | Get source IP address |
languages |
1.9+ | Get languages met in a message |
list |
2.0+ | Returns a list of values from its arguments or an empty list |
messageid |
2.6+ | Get message ID |
pool_var |
1.8+ | Get specific pool var. The first argument must be variable name, the second argument is optional and defines the type (string by default) |
queueid |
2.6+ | Get queue ID |
rcpts |
1.8+ | Get MIME or SMTP rcpts (e.g. rcpts('smtp') or rcpts('mime'), uses any type by default) |
received |
1.8+ | Get list of received headers. If no arguments specified, returns list of tables. Otherwise, selects a specific element, e.g. by_hostname |
request_header |
1.8+ | Get specific HTTP request header. The first argument must be header name. |
symbol |
2.6+ | Get symbol with the name that is expected as first argument. Returns the symbol table (like task:get_symbol()) |
time |
1.8+ | Get task timestamp. The first argument is type:
|
to |
1.8+ | Get principal recipient |
uid |
2.6+ | Get ID of the task being processed |
urls |
1.8+ | Get list of all urls. If no arguments specified, returns list of url objects. Otherwise, calls a specific method, e.g. get_tld |
user |
1.8+ | Get authenticated user name |
Transformation functions
| Transform method | Version | Description |
|---|---|---|
append |
2.0+ | Appends a string or a strings list |
apply_map |
2.0+ | Returns a value from some map corresponding to some key (or acts like a map function). Map name must be registered first! |
digest |
1.8+ | Create a digest from a string. The first argument is encoding (hex, base32, base64), the second argument is optional hash type (blake2, sha256, sha1, sha512, md5) |
drop_n |
1.8+ | Returns list without the first n elements |
equal |
2.0+ | Boolean function equal. Returns either nil or its argument if input is equal to argument |
filter_map |
2.0+ | Returns a value if it exists in some map (or acts like a filter function). Map name must be registered first! |
first |
1.8+ | Returns the first element |
id |
1.8+ | Drops input value and return values from function’s arguments or an empty string |
in |
1.8+ | Boolean function in. Returns either nil or its input if input is in args list |
inverse |
2.0+ | Inverses input. Empty string comes the first argument or true, non-empty string comes nil |
ipmask |
2.0+ | Applies mask to IP address. The first argument is the mask for IPv4 addresses, the second is the mask for IPv6 addresses. |
join |
1.8+ | Joins strings into a single string using separator in the argument |
last |
1.8+ | Returns the last element |
lower |
1.8+ | Returns the lowercased string |
not_in |
1.8+ | Boolean function not in. Returns either nil or its input if input is not in args list |
nth |
1.8+ | Returns the n-th element |
prepend |
2.0+ | Prepends a string or a strings list |
regexp |
1.8+ | Regexp matching |
sort |
2.0+ | Sort strings lexicographically |
substring |
1.8+ | Extracts substring. Arguments are equal to lua string.sub |
take_n |
1.8+ | Returns the n first elements |
to_ascii |
2.6+ | Returns the string with all non-ascii bytes replaced with the character given as second argument or ? |
uniq |
2.0+ | Returns a list of unique elements (using a hash table - no order preserved!) |
You can access the latest list of all selector functions and also test Rspamd selector pipelines through the integrated Web Interface. This provides you with a convenient way to explore and experiment with Rspamd’s selector capabilities.
Maps in transformations
Starting from version 2.0, Rspamd introduces support for using maps within selectors. This is achieved by incorporating maps into a designated lua_selectors.maps table. The table should consist of name-value pairs where the name represents the symbolic name of the map, which can be employed in extraction or transformation functions, and the value is the output of lua_maps.map_add_from_ucl. To illustrate this concept:
local lua_selectors = require "lua_selectors"
local lua_maps = require "lua_maps"
lua_selectors.maps.test_map = lua_maps.map_add_from_ucl({
'key value',
'key1 value1',
'key3 value1',
}, 'hash', 'test selectors maps')
local samples = {
["map filter"] = {
selector = "id('key').filter_map(test_map)",
expect = {'key'}
},
["map apply"] = {
selector = "id('key').apply_map(test_map)",
expect = {'value'}
},
["map filter list"] = {
selector = "list('key', 'key1', 'key2').filter_map(test_map)",
expect = {{'key', 'key1'}}
},
["map apply list"] = {
selector = "list('key', 'key1', 'key2', 'key3').apply_map(test_map)",
expect = {{'value', 'value1', 'value1'}}
},
["map apply list uniq"] = {
selector = "list('key', 'key1', 'key2', 'key3').apply_map(test_map).uniq",
expect = {{'value1', 'value'}}
},
}
Type safety
All selectors provide type safety controls. It means that Rspamd checks if types within pipeline match each other. For example, rcpts extractor returns a list of addresses, and from returns a single address. If you need to lowercase this address you need to convert it to a string as the first step. This could be done by getting a specific element of this address, e.g. from.addr -> this returns a string (you could also get from.name to get a displayed name, for example). Each processor has its own list of the accepted types.
However, even when dealing with recipients, where rcpt generates a list of addresses, you can still employ the same pipeline, such as rcpts.addr.lower. This versatility is possible because many processors can be functionally applied like a map:
elt1 -> f(elt1) -> elt1'
elt2 -> f(elt2) -> elt2'
elt3 -> f(elt3) -> elt3'
Hence, a list of elements of type t undergoes an element-wise transformation using processor f, creating a new list of type t1 (which can be the same as t). The length of the resulting list remains unchanged.
To enhance convenience, the ultimate values can be implicitly converted to their string representation. This is particularly applicable to URLs, email addresses, and IP addresses, all of which can be seamlessly converted to strings.
In general, you need not be overly concerned about type safety unless you encounter actual type errors. This mechanism serves to safeguard the selectors framework from inadvertent user errors.
Own selectors
You have the option to incorporate your custom extractors and processing functions. However, it’s crucial to implement this setup before utilizing these selectors in any other context. For instance, the execution of rspamd.local.lua precedes the initialization of plugins, making it a secure location to register your functions. Here is a small example about how to register your own extractors and processors.
local lua_selectors = require "lua_selectors" -- Import module
lua_selectors.register_extractor(rspamd_config, "get_something", {
get_value = function(task, args) -- mandatory field
return task:get_something(),'string' -- result + type
end,
description = 'Sample extractor' -- optional
})
lua_selectors.register_processor(rspamd_config, "append_string", {
types = {['string'] = true}, -- accepted types
process = function(input, type, args)
return input .. table.concat(args or {}),'string' -- result + type
end,
map_type = 'string', -- can be used in map like invocation, always return 'string' type
description = 'Adds all arguments to the input string'
})
-- List processor example
lua_selectors.register_transform(rspamd_config, "take_second", {
types = {['list'] = true}, -- accepted types
process = function(input, t)
return input[2],t:match('^(.*)_list$') -- second element and list type
end,
desctiption = 'Returns the second element of the list'
})
You can use these functions in your selectors subsequently.
Regular expressions selectors
You can also leverage selectors with Rspamd’s regexp module. This approach allows you to utilize the data extracted and processed by the selector framework to match it against various regular expressions.
To start, you’ll need to register a selector in the regexp module. You can achieve this by adding the following code to your rspamd.local.lua file:
rspamd_config:register_re_selector('test', 'user.lower;header(Subject).lower', ' ')
The first argument denotes the symbolic name of the selector, which you will subsequently use to reference it in regular expression rules. The second argument entails the selector in the usual syntax. The last argument, which is optional, designates the character used to concatenate the different selector parts. In this manner, the selector generates a value by joining the authenticated user and the Subject header’s value using a space character.
Following this, you can refer to this selector in your regular expression rules. The order in which you use the selector’s name and its registration in the code doesn’t impact its functionality.
config['regexp']['TEST_SELECTOR_RE'] = {
re = 'test=/user some subject/$',
score = 100500,
}
The syntax for regular expressions involving selectors bears some resemblance to header regular expressions. You begin by stating the selector’s name, followed by = and the actual regular expression, concluded with $ to signify the type. The omission of the $ sign alerts Rspamd that you are specifying a header regular expression, rather than a selector-based one. It is essential to include this symbol to ensure clarity. Alternatively, you can utilize the extended syntax for the re type:
config['regexp']['TEST_SELECTOR_RE'] = {
re = 'test=/user some subject/{selector}',
score = 100500,
}
If a selector yields multiple values, such as recipients, the corresponding regular expression will be matched against all the elements within that list. Consequently, it becomes crucial to incorporate the one_shot option to prevent inadvertent insertion of multiple symbols:
rspamd_config:register_re_selector('test_rcpt', 'rcpts.addr.lower;header(Subject).lower', ' ')
config['regexp']['TEST_SELECTOR_RCPT'] = {
re = 'test_rcpt=/user@example.com some subject/{selector}',
score = 100500,
one_shot = true,
}
It’s noteworthy that data retrieved through selectors is internally cached, allowing you to safely reuse it across multiple regular expressions (in case of Hyperscan support multiple regular expressions will also be composed as usually).